Evaluation of hashing algorithms Ascon, SHA256, SHA512 and BLAKE3 on an ARM Cortex M7 processor
Here we evaluate the execution performance and code size of various hashing algorithms on a STM32F767 Cortex M7 processor.
Test setup
The tests are run on a NUCLEO-F767 board which has a STM32F767 Cortex M7 processor. This processor has 512 KiB of RAM, of which 128KiB is Data Tightly Coupled Memory(DTCM)1. The DTCM is directly connected to the core and should provide faster memory access compared to the rest of the 384KiB of SRAM. Therefore all the tests are run twice, once with the data in DTCM and then in ordinary SRAM. The tests are done with an input buffer size of 120KiB.
The firmware was generated using ST’s CubeMX code generator tool. The tests run on bare metal without any RTOS. The code was compiled with GCC 14.2.1 from Debian repository. The timing is measured using the CYCCNT counter, which increments with each CPU clock cycle, enabling precise measurement of the execution time for the hash algorithm.
Algorithms tested
- Ascon
- SHA256 and SHA512 from MbedTLS
- BLAKE3
- CRC32 using the hardware CRC in the microcontroller
- XOR of all bytes in the buffer
Results
Built with -Os
The armv7m variant of Ascon is used and the code is built with -Os
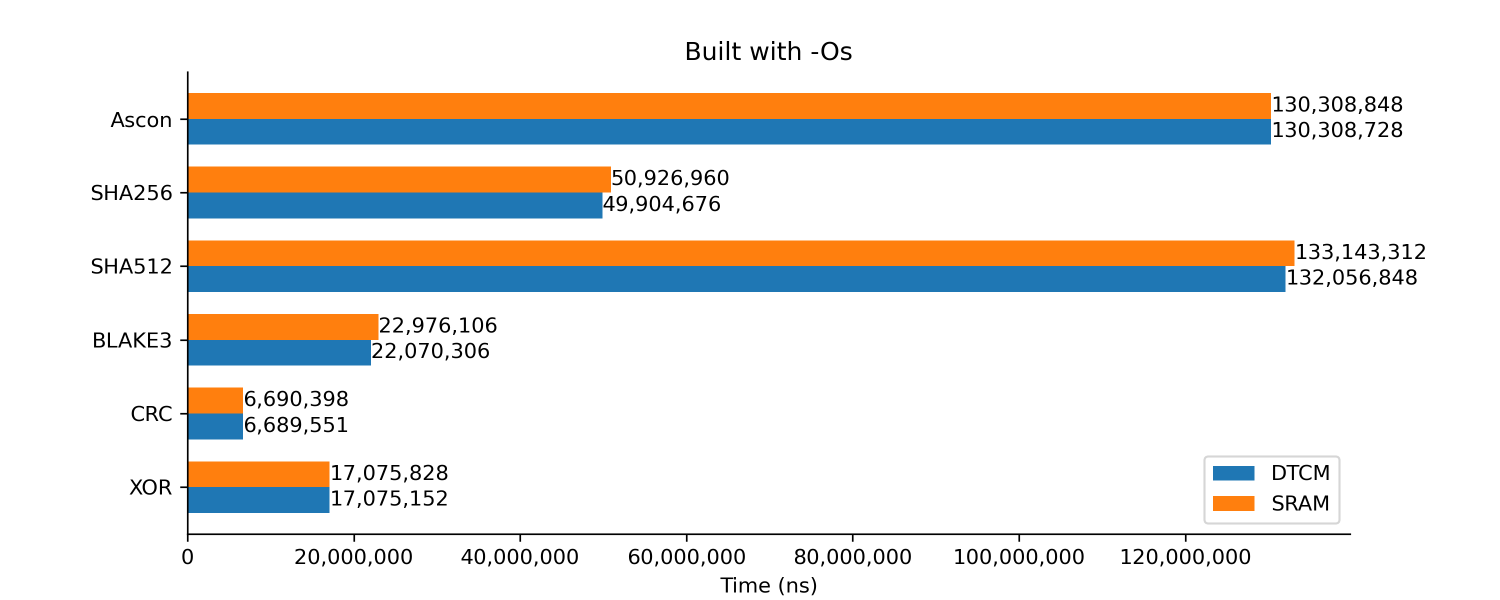
From the results above, we can see that the DTCM RAM barely makes any difference in performance. BLAKE3 is the most impressive of all with performance close to that of the hardware CRC. As you will soon see, it gets even closer in the upcoming tests.
XOR is signifcantly slower than CRC probably because the data was processed serially, one byte at a time.
// XOR calculation
uint32_t xor = 0;
for (size_t i = 0; i < length; i++) {
xor ^= buffer[i];
}
// CRC calculation by ST CubeMX driver
for (i = 0U; i < (BufferLength / 4U); i++)
{
hcrc->Instance->DR = ((uint32_t)pBuffer[4U * i] << 24U) | \
((uint32_t)pBuffer[(4U * i) + 1U] << 16U) | \
((uint32_t)pBuffer[(4U * i) + 2U] << 8U) | \
(uint32_t)pBuffer[(4U * i) + 3U];
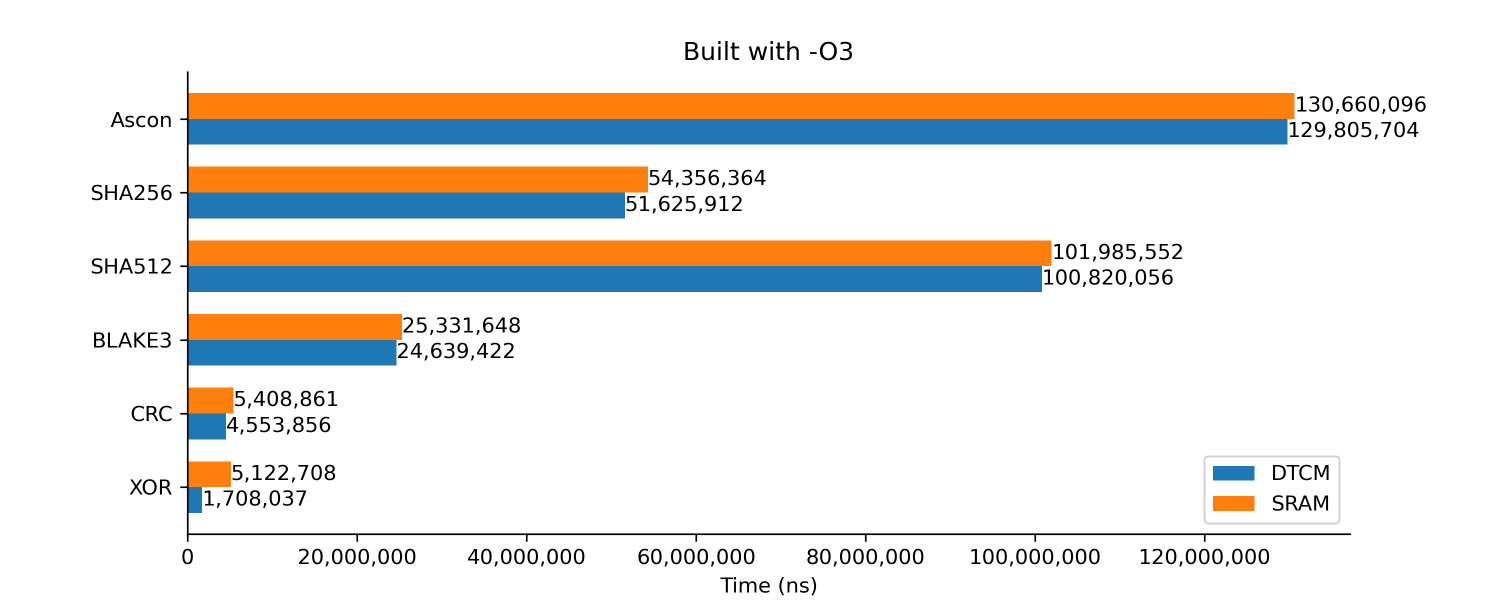
}Built with -O3
This test is similar to above, but with optimization flag set to level 3
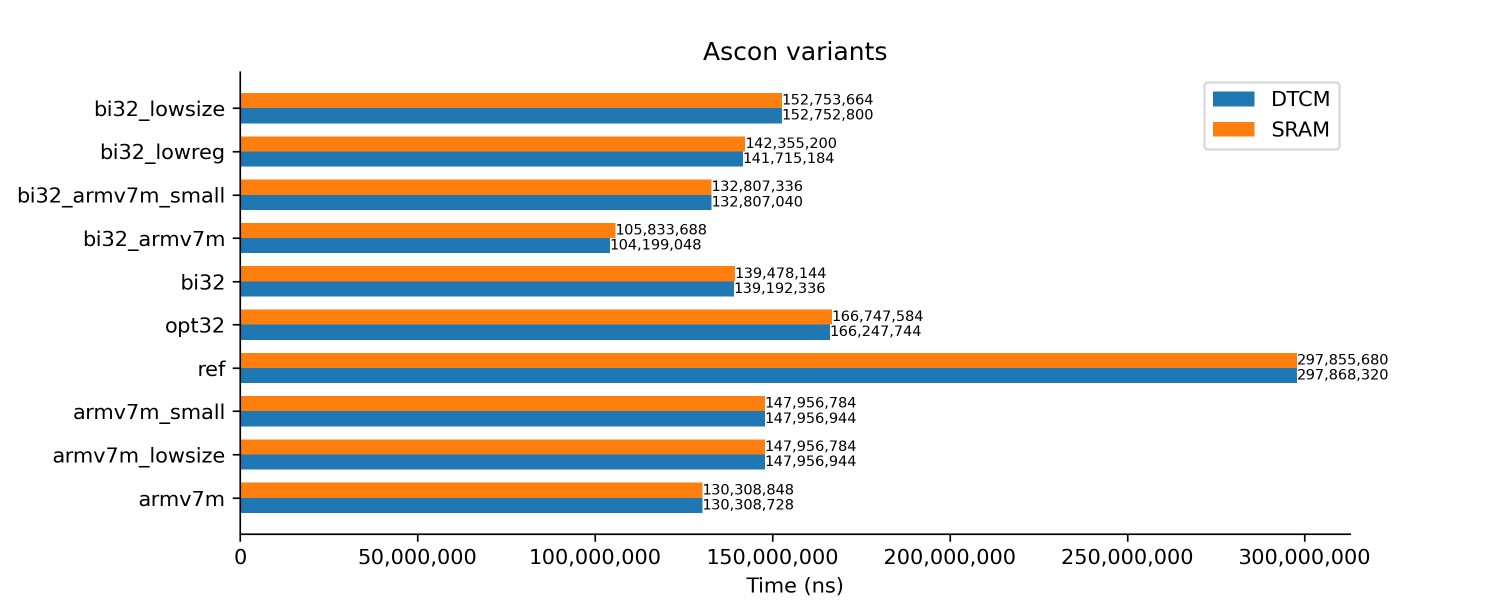
Ascon variants
Here we test the different variants of Ascon. Code is compiled with -Os for all the tests.
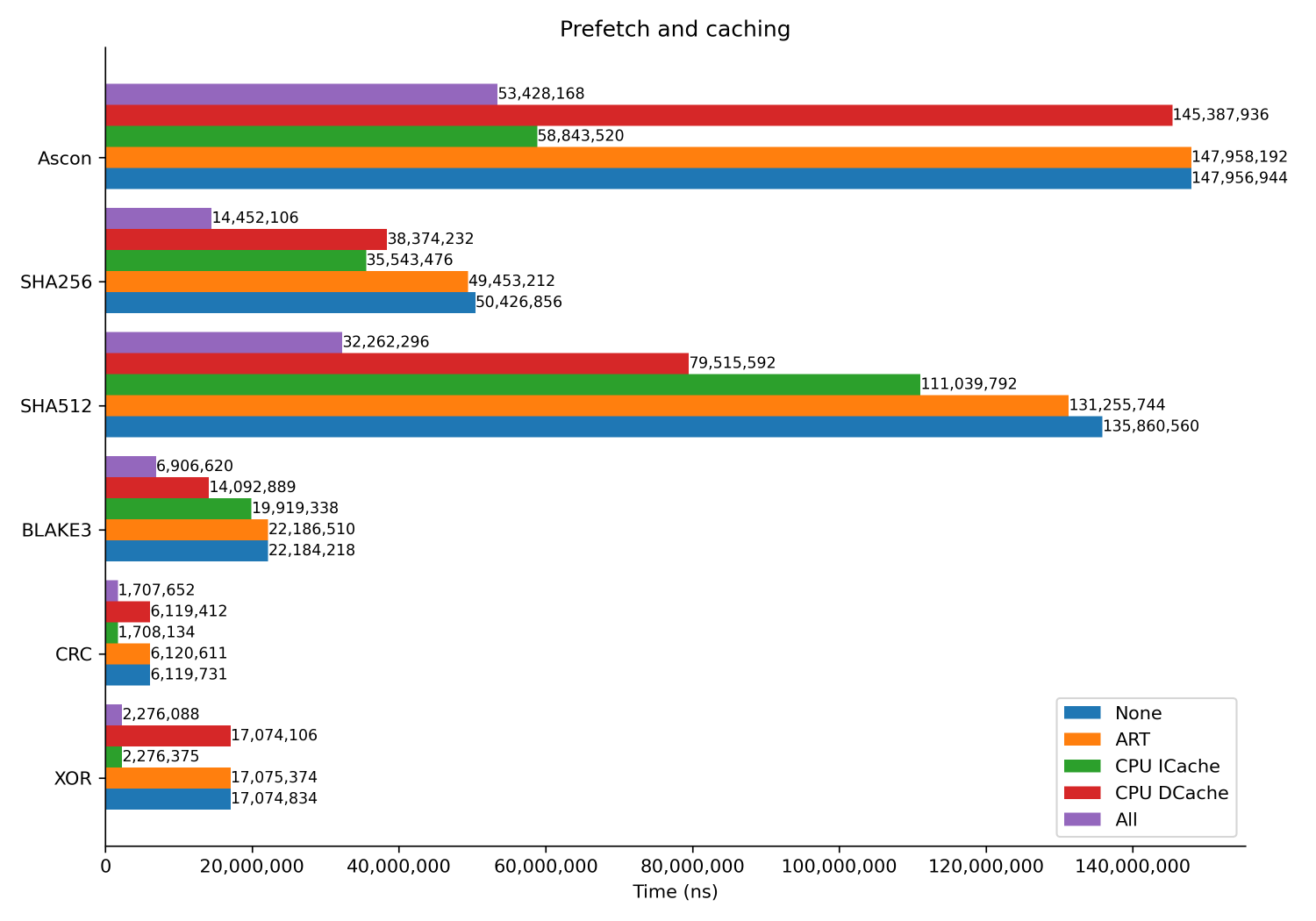
Prefetch and caching
We test the effects of enabling the following
- Adaptive realtime accelerator (ART)
- CPU Instruction cache
- CPU Data cache
The armv7m_small variant of Ascon is used and the code is built with -Os. The buffer is stored in DTCM RAM.
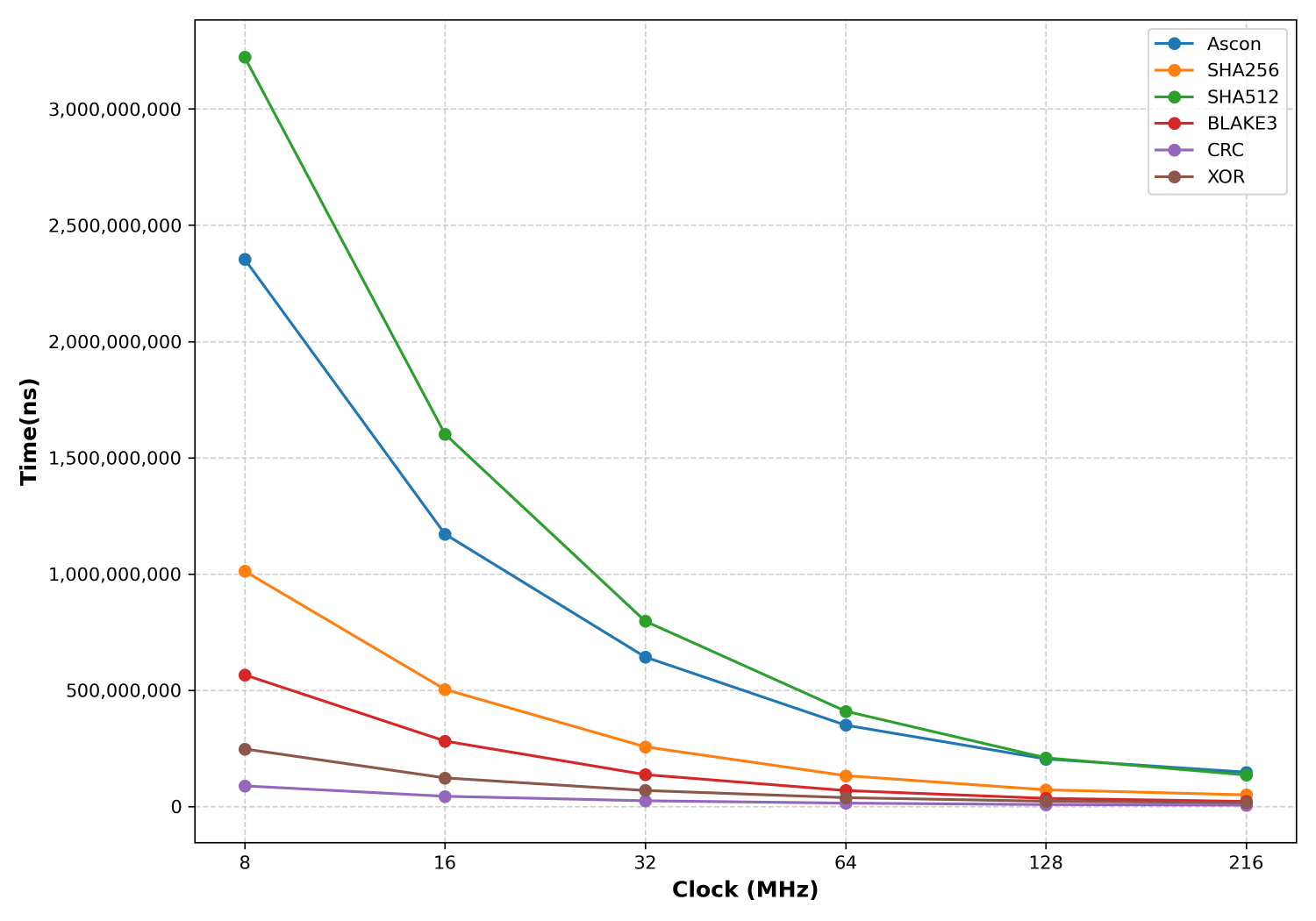
Clock speeds
We measure the time taken across different CPU clock speeds (HCLK). The armv7m_small variant of Ascon is used and the code is built with -Os. The buffer is stored in DTCM RAM.
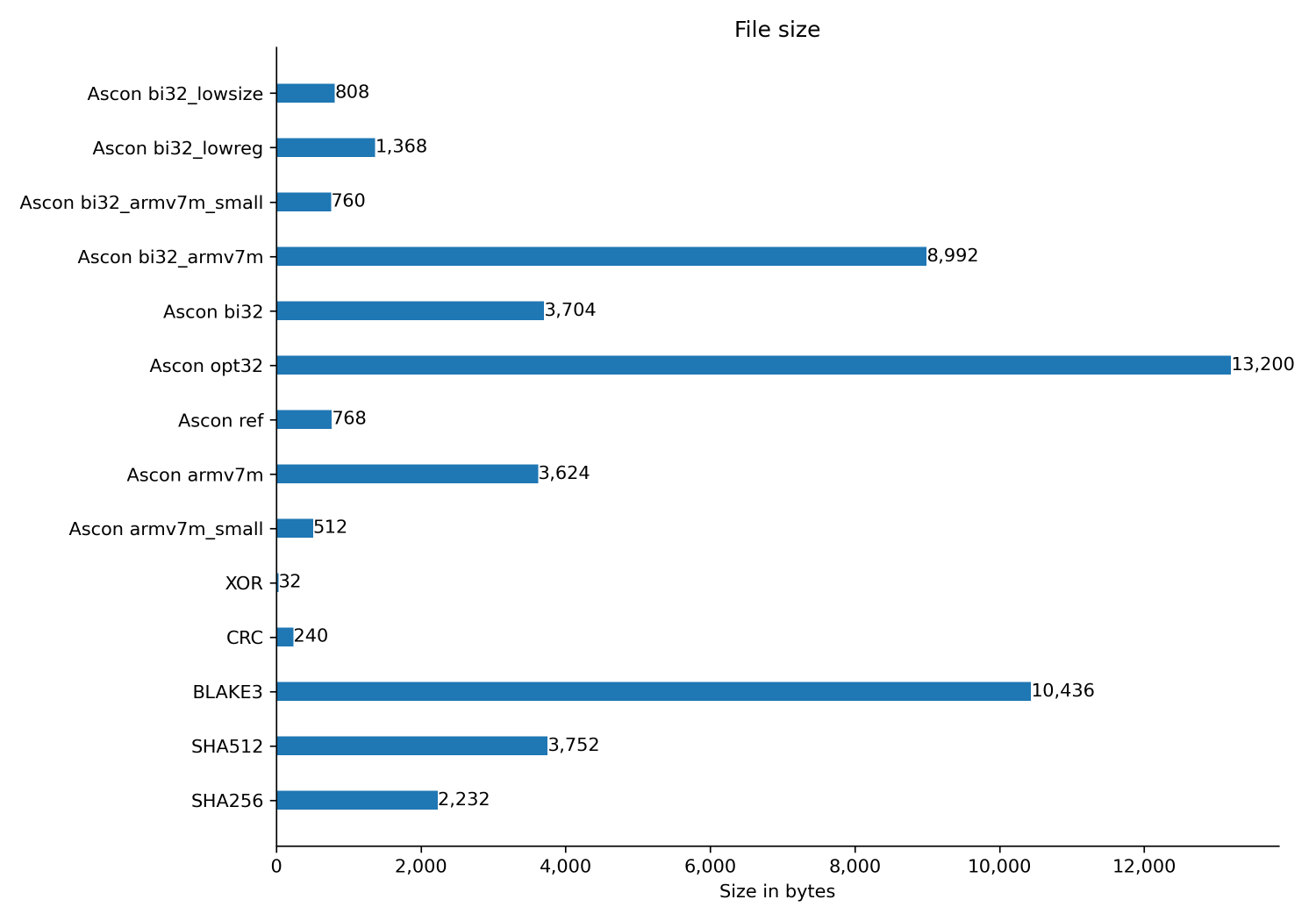
Flash size
Here we measure the binary size of the various algorithms. The code is compiled with -Os and -flto